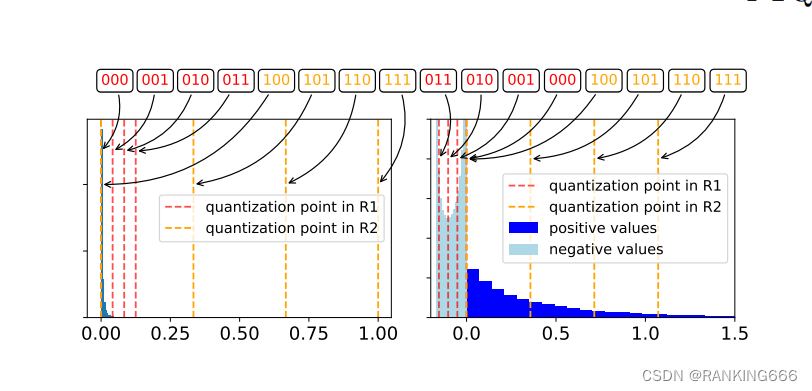
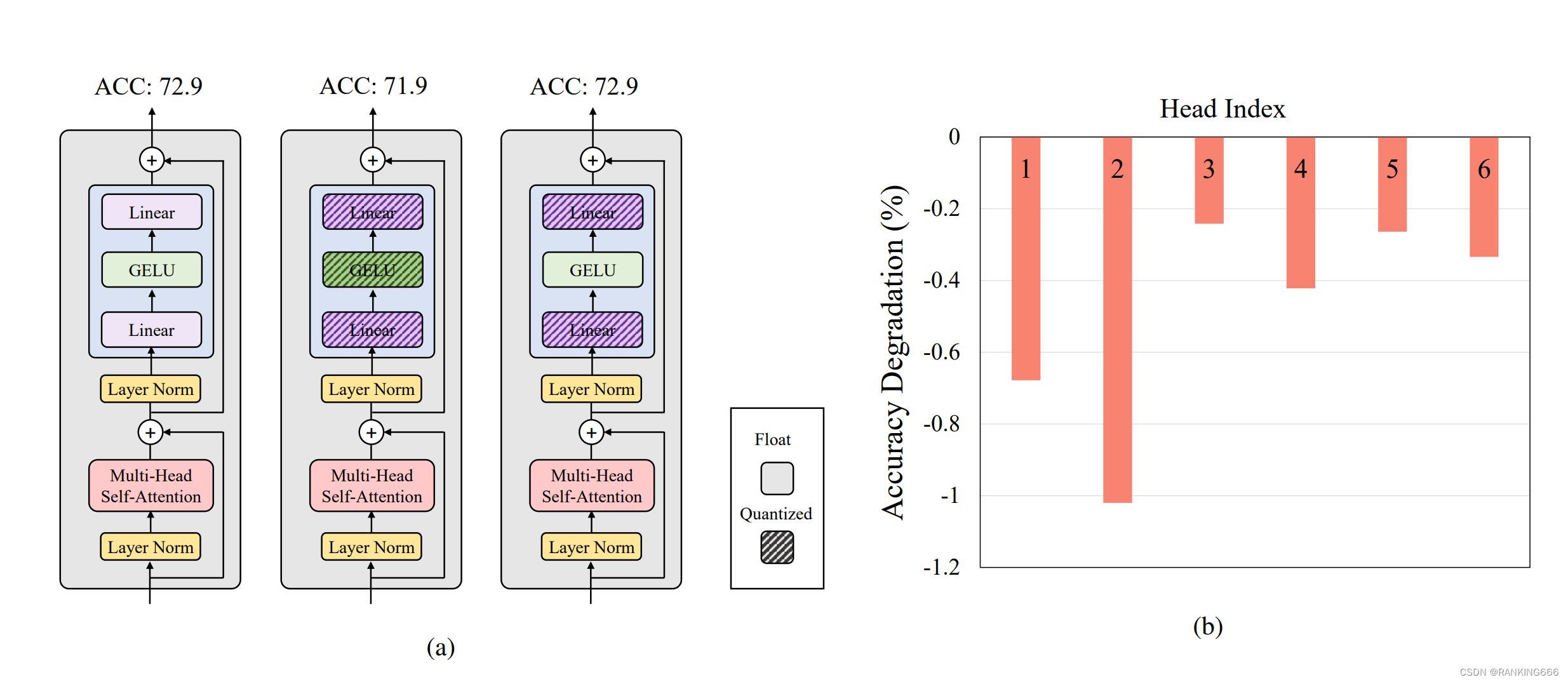
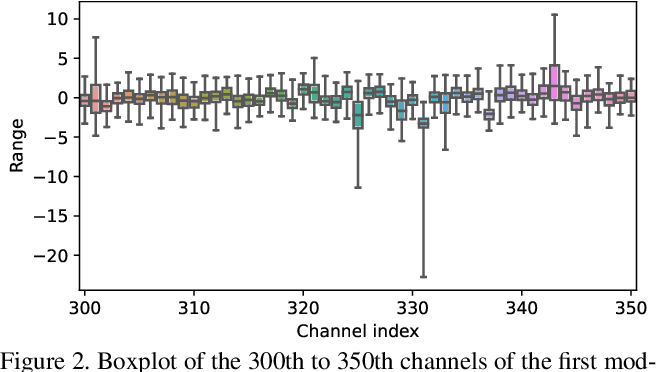
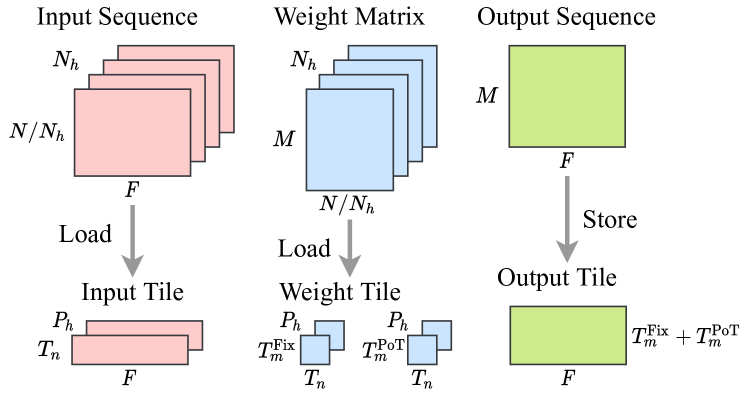
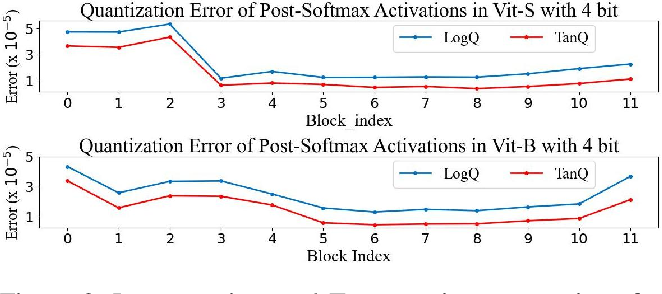
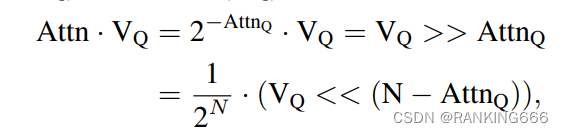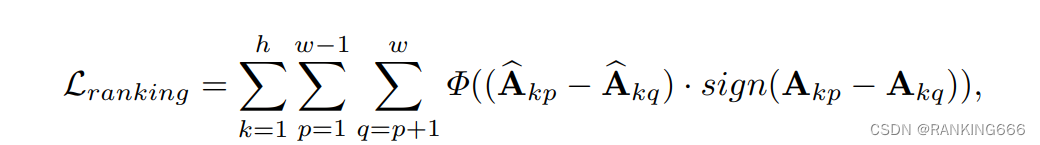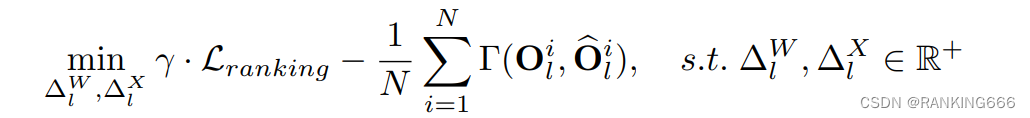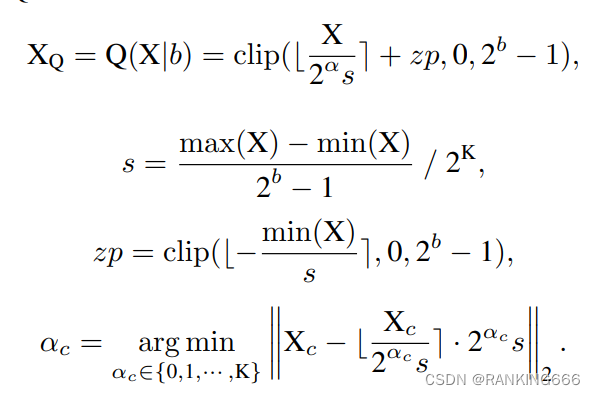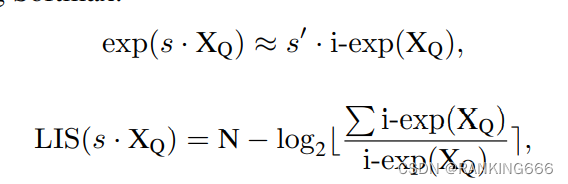Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
VIT quantization相关论文阅读_post-training quantization for vision ...
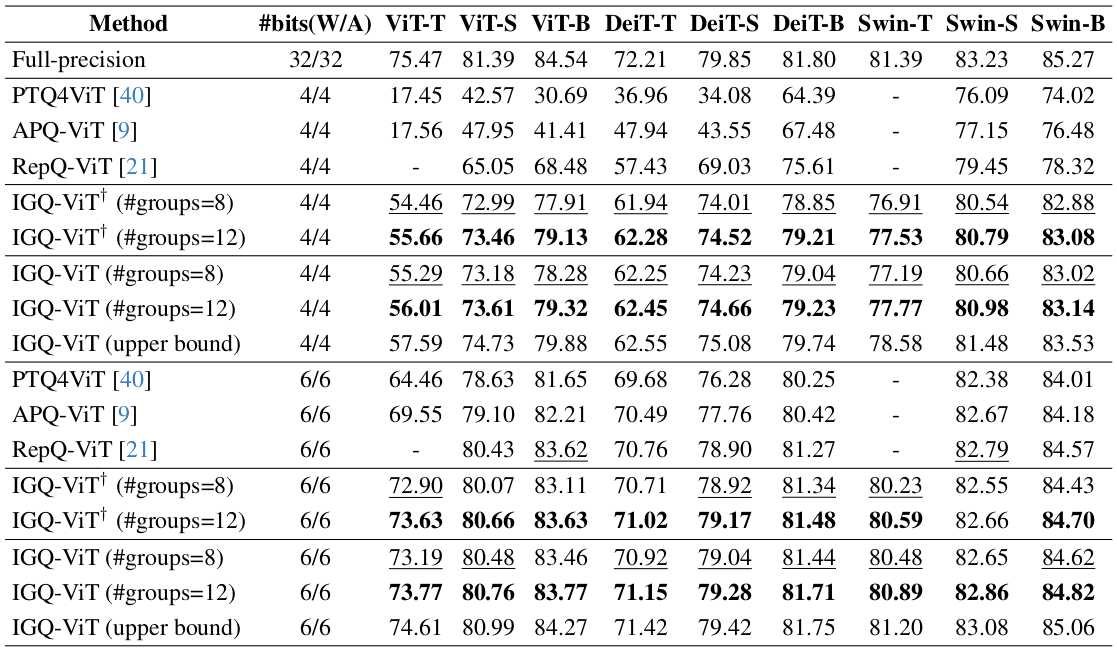
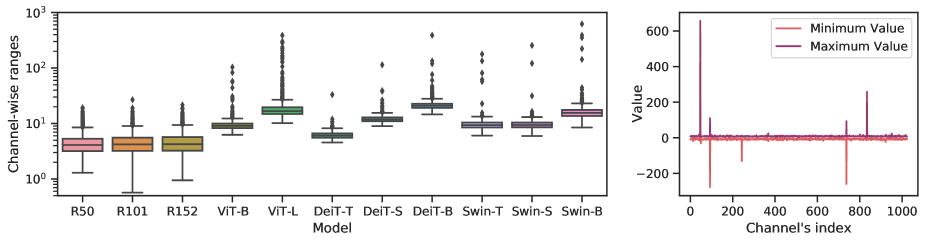
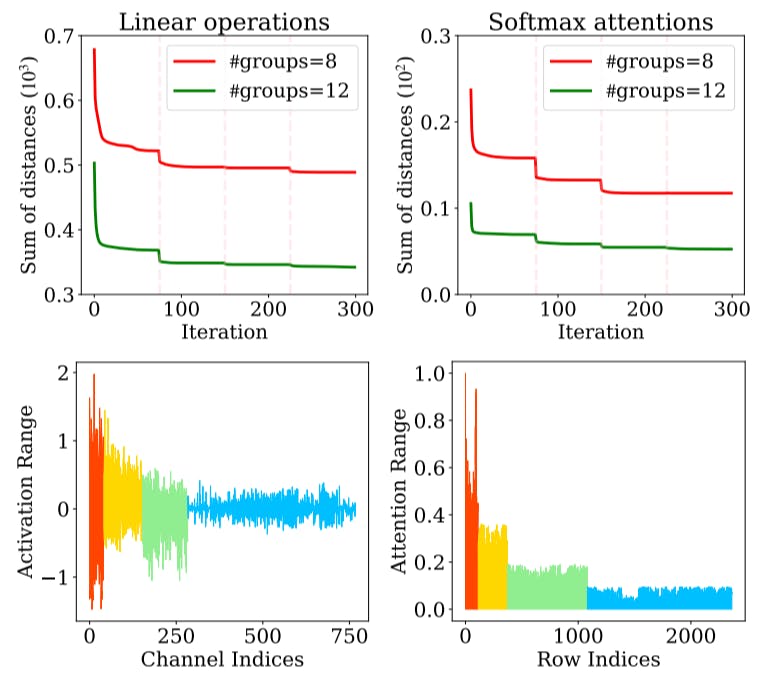
Instance-Aware Group Quantization for Vision Transformers
Q-ViT: Fully Differentiable Quantization for Vision Transformer | DeepAI
PoMQ-ViT: Mixed-Precision Quantization Vision Transformer with Pareto ...
Trio-ViT: Post-Training Quantization and Acceleration for Softmax-Free ...
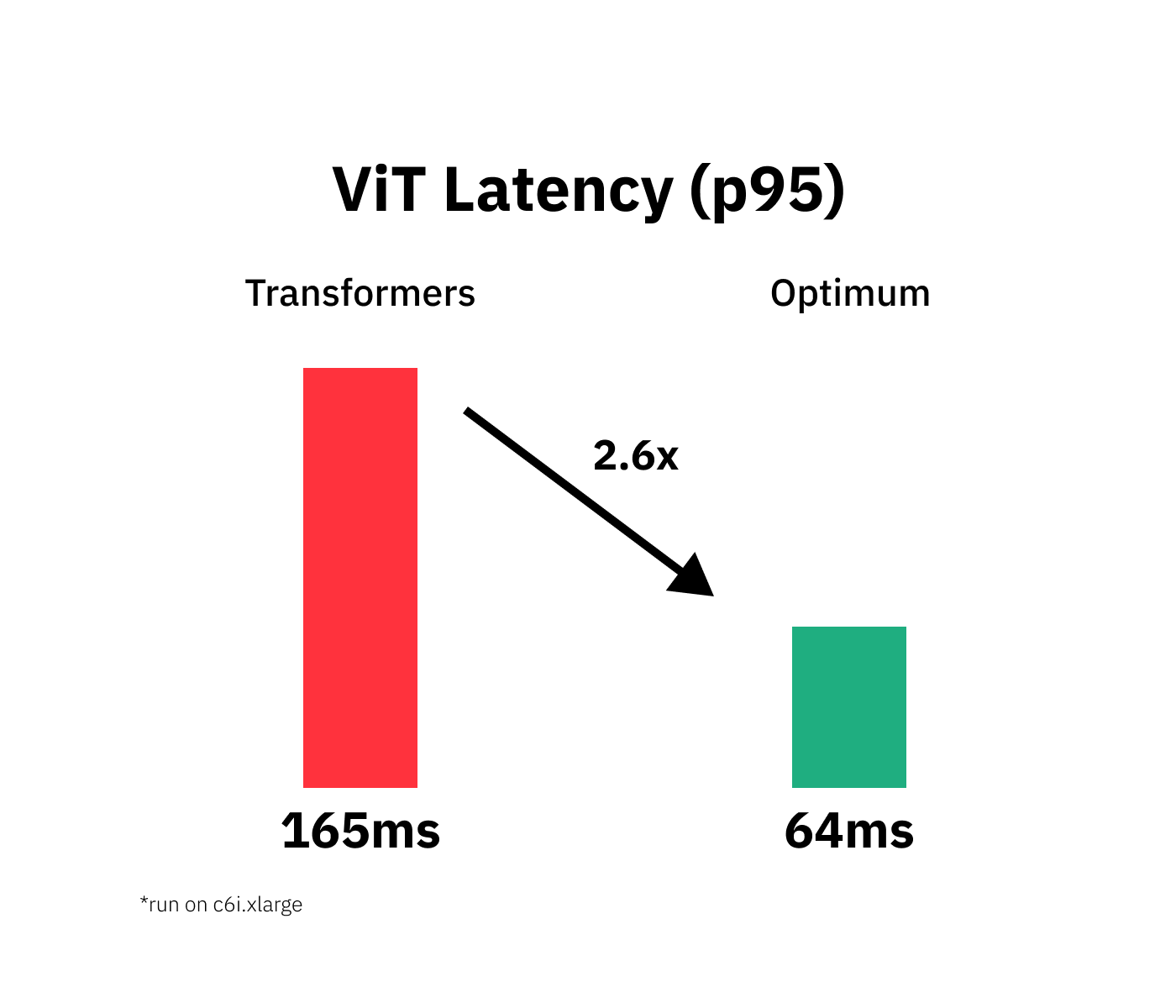
Accelerate Vision Transformer (ViT) with Quantization using Optimum
Bi-Vit: Pushing The Limit Of Vision Transformer Quantization – VACMTS
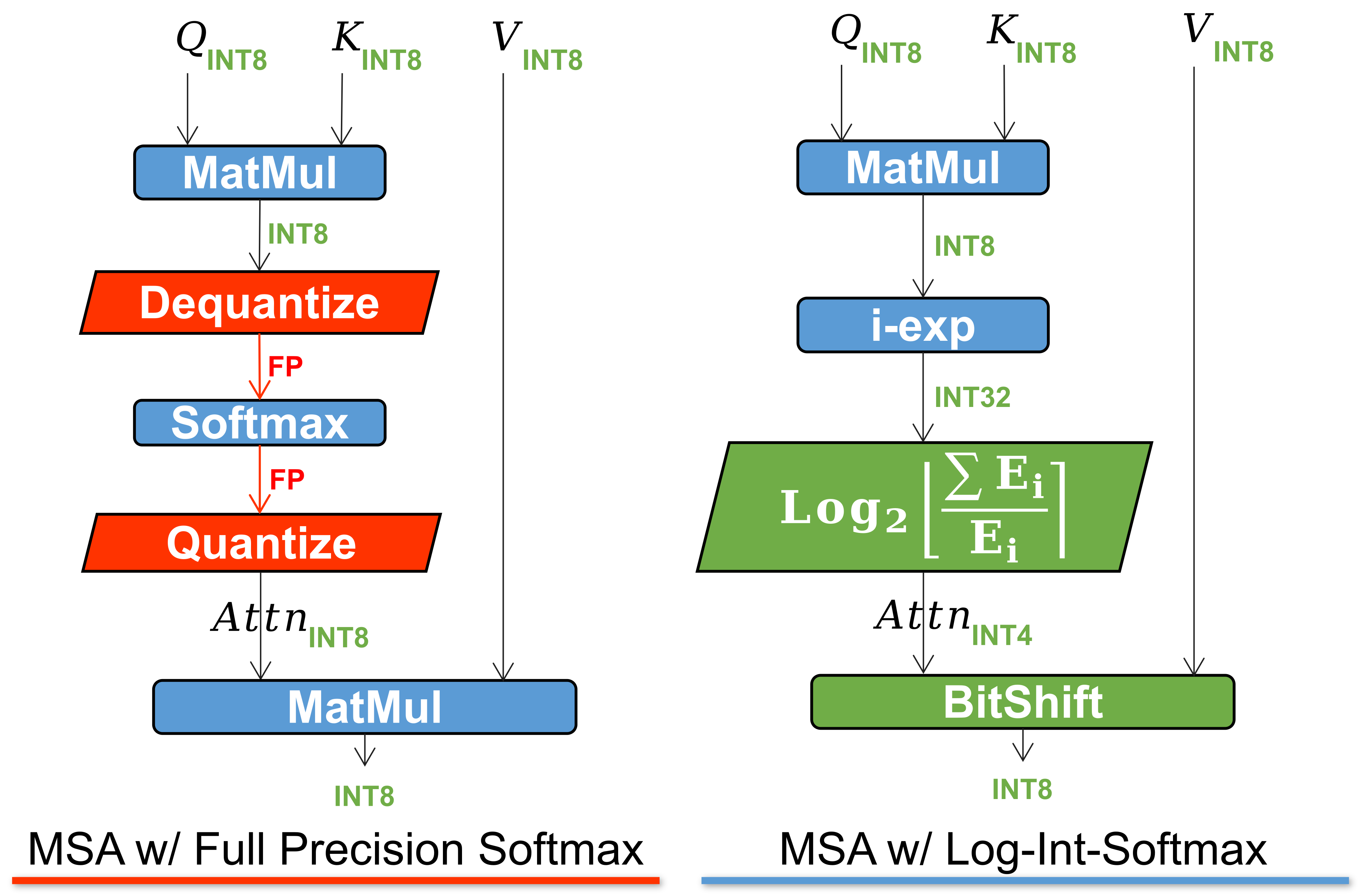
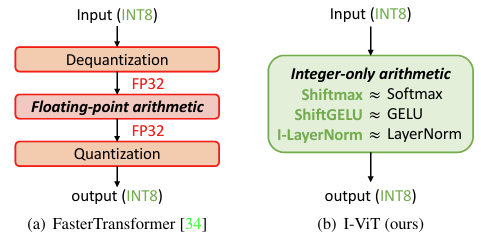
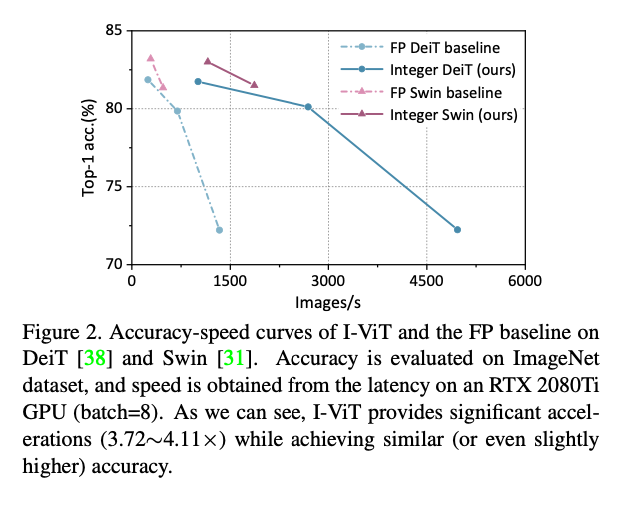
I-ViT Integer-only Quantization for Efficient Vision Transformer ...
TSPTQ-ViT: TWO-SCALED POST-TRAINING QUANTIZATION FOR VISION TRANSFORMER ...
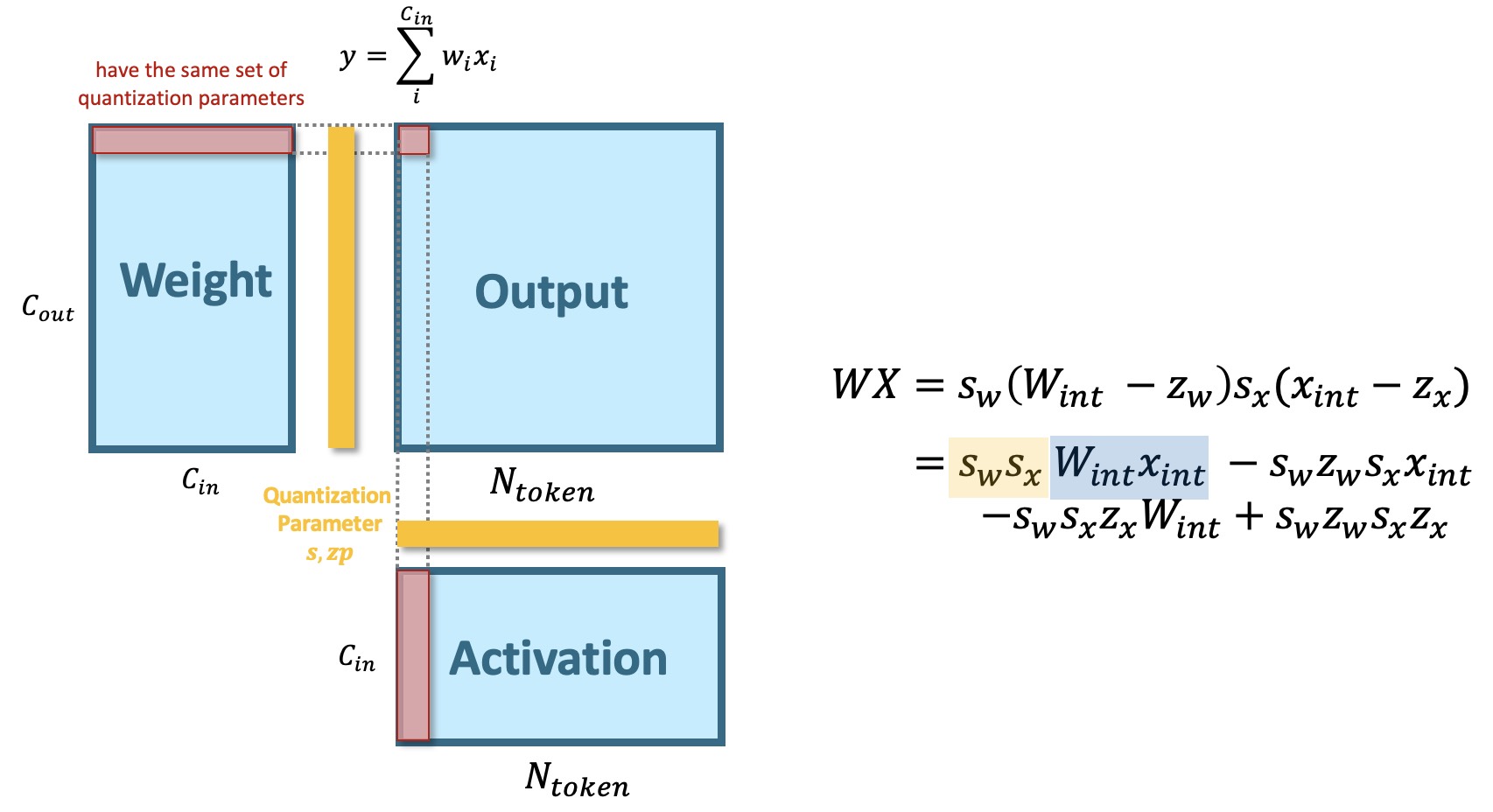
[2111.13824] FQ-ViT: Post-Training Quantization for Fully Quantized ...
(PDF) Bi-ViT: Pushing the Limit of Vision Transformer Quantization
Table 1 from Q-ViT: Fully Differentiable Quantization for Vision ...
FQ-ViT: Post-Training Quantization for Fully Quantized Vision ...
(PDF) TSPTQ-ViT: Two-scaled post-training quantization for vision ...
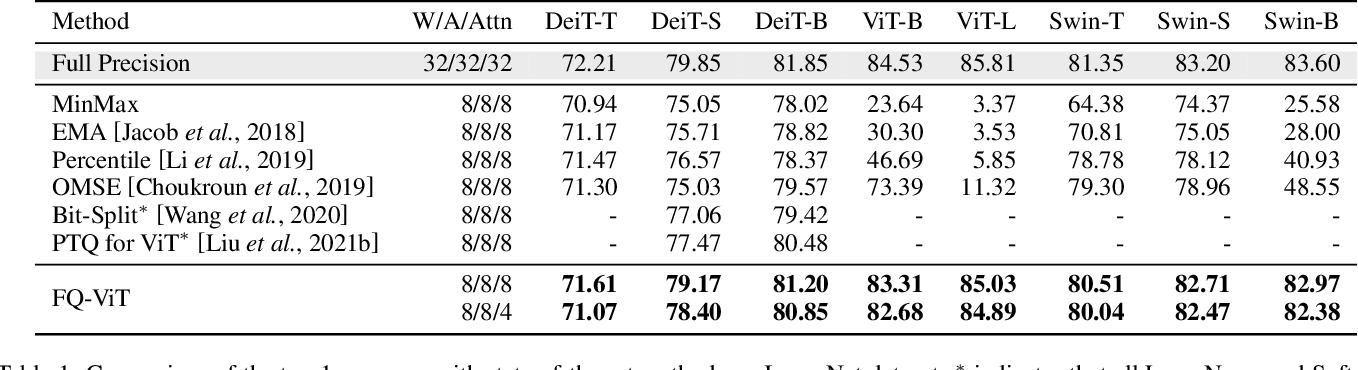
Table 1 from FQ-ViT: Post-Training Quantization for Fully Quantized ...
Paper page - MPTQ-ViT: Mixed-Precision Post-Training Quantization for ...
PSAQ-ViT V2: Towards Accurate and General Data-Free Quantization for ...
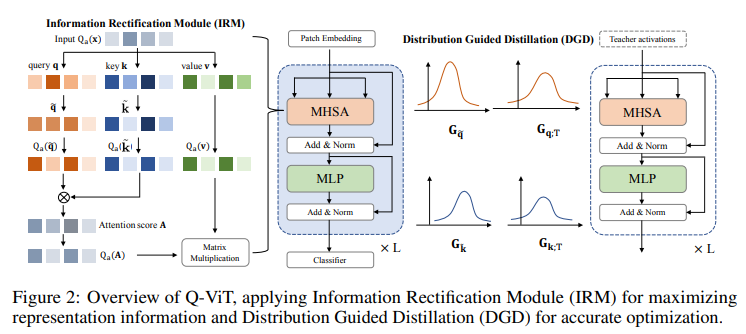
[논문 리뷰] APHQ-ViT: Post-Training Quantization with Average Perturbation ...
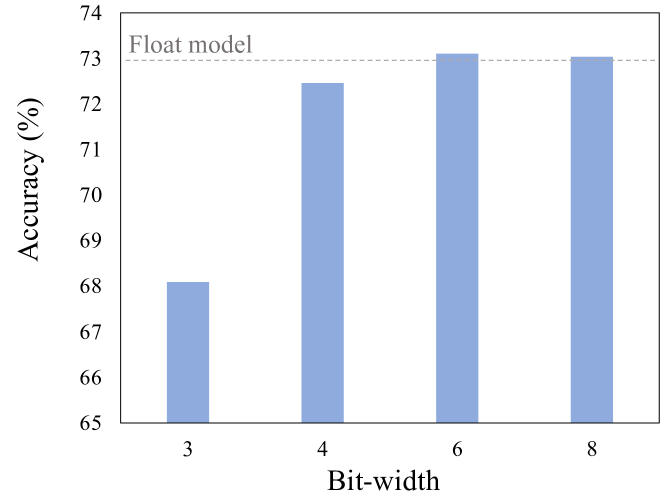
Quantized_ViT/4-bit quantization at main · LongAoTianxia/Quantized_ViT ...
[2201.07703] Q-ViT: Fully Differentiable Quantization for Vision ...
[PDF] Trio-ViT: Post-Training Quantization and Acceleration for Softmax ...
Bi-ViT: Pushing the Limit of Vision Transformer Quantization | Underline
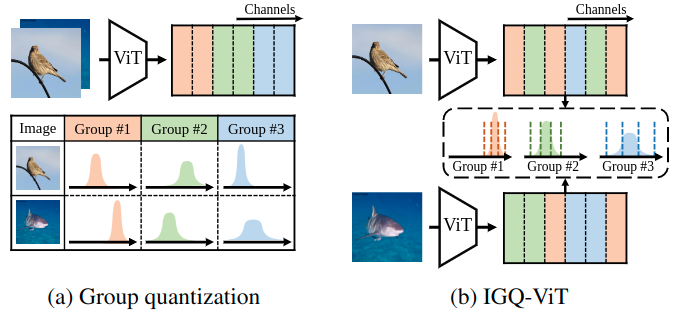
IGQ-ViT: Instance-Aware Group Quantization for Low-Bit Vision ...
Paper page - I-ViT: Integer-only Quantization for Efficient Vision ...
論文解説|I-ViT:Integer-only Quantization for Efficient Vision Transformer…
Paper page - APHQ-ViT: Post-Training Quantization with Average ...
(PDF) Variation-aware Vision Transformer Quantization
RepQ-ViT: Scale Reparameterization for Post-Training Quantization of ...
P$^2$-ViT: Power-of-Two Post-Training Quantization and Acceleration for ...
Bi-ViT: Pushing the Limit of Vision Transformer Quantization | DeepAI
I-ViT: Integer-only Quantization for Efficient Vision Transformer ...
ViDiT-Q: Efficient and Accurate Quantization of Diffusion Transformers ...
GitHub - zkkli/I-ViT: [ICCV 2023] I-ViT: Integer-only Quantization for ...
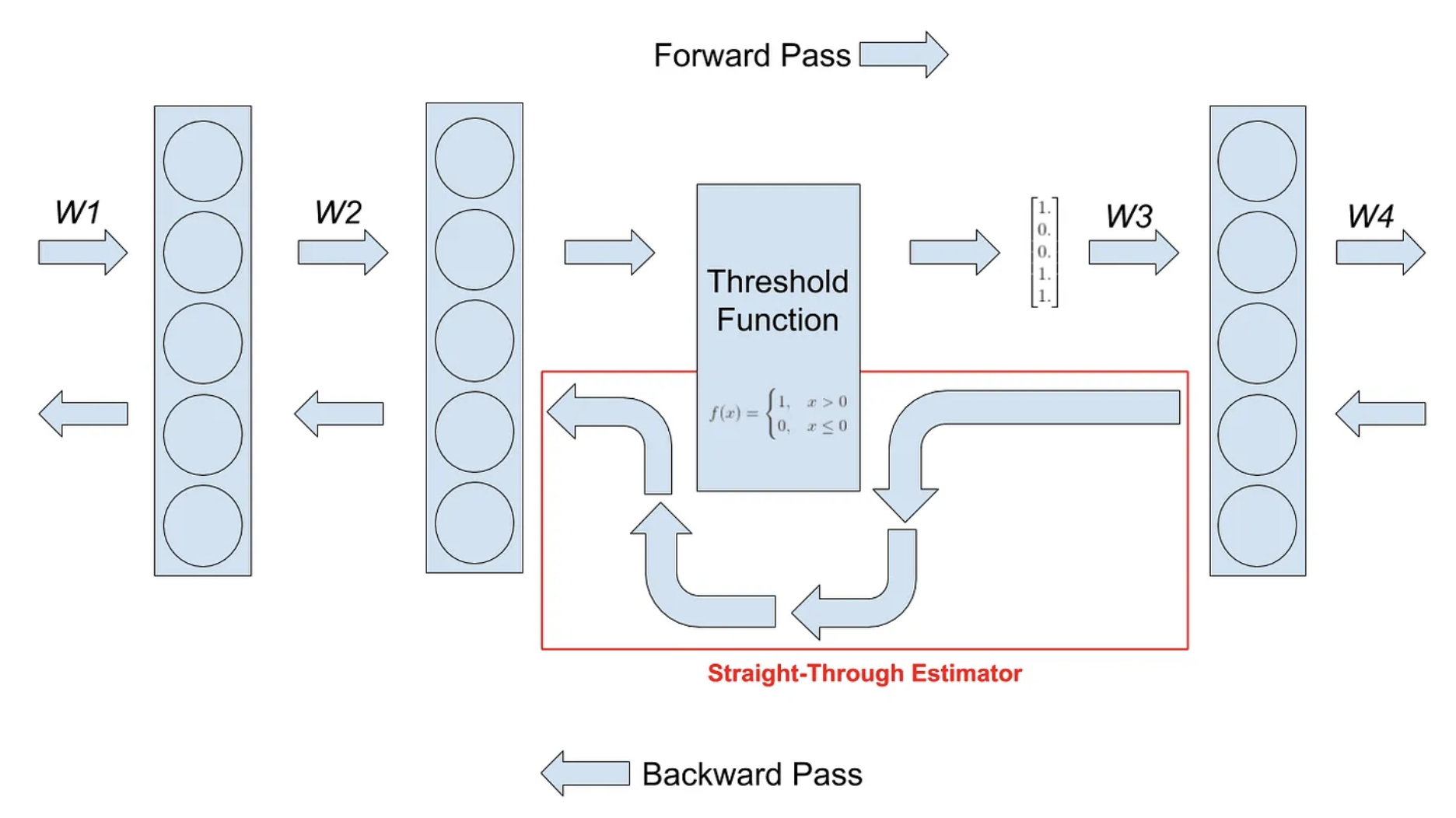
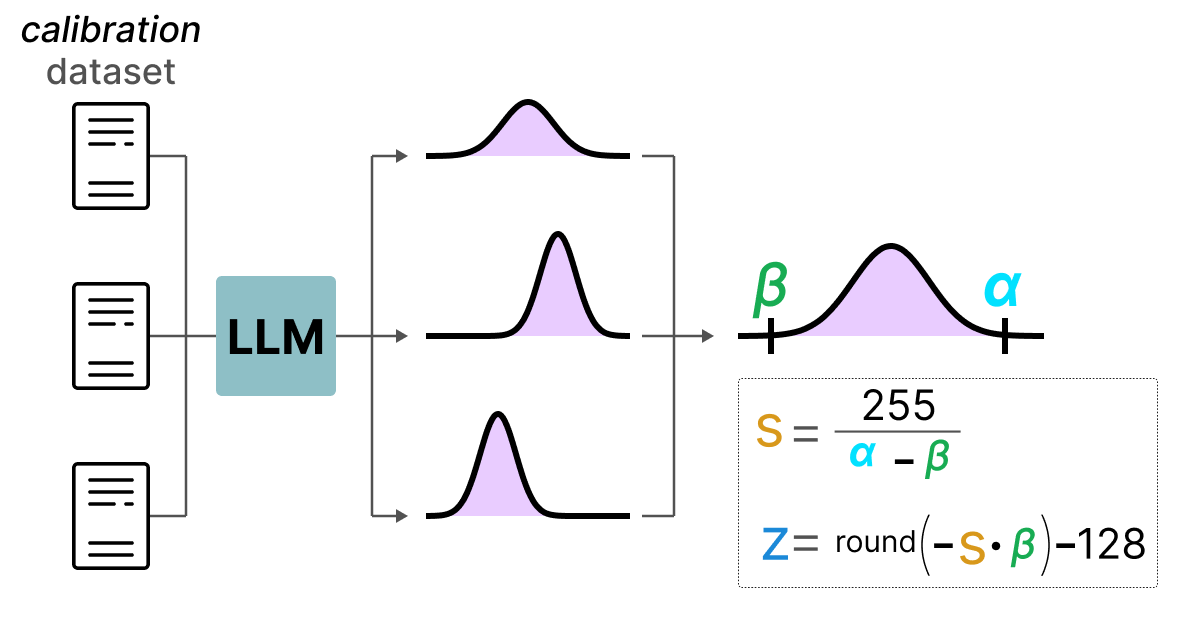
A Visual Guide to Quantization - by Maarten Grootendorst
Overview of the RepQ-ViT framework. Building on the... | Download ...
Quasar-ViT: Hardware-Oriented Quantization-Aware Architecture Search ...
GitHub - GoatWu/APHQ-ViT: [CVPR 2025] APHQ-ViT: Post-Training ...
Launchpad.ai: Q-ViT: Accurate and Fully Quantized Low-bit Vision ...
Q-ViT: Accurate and Fully Quantized Low-bit Vision Transformer(NeurlPS ...
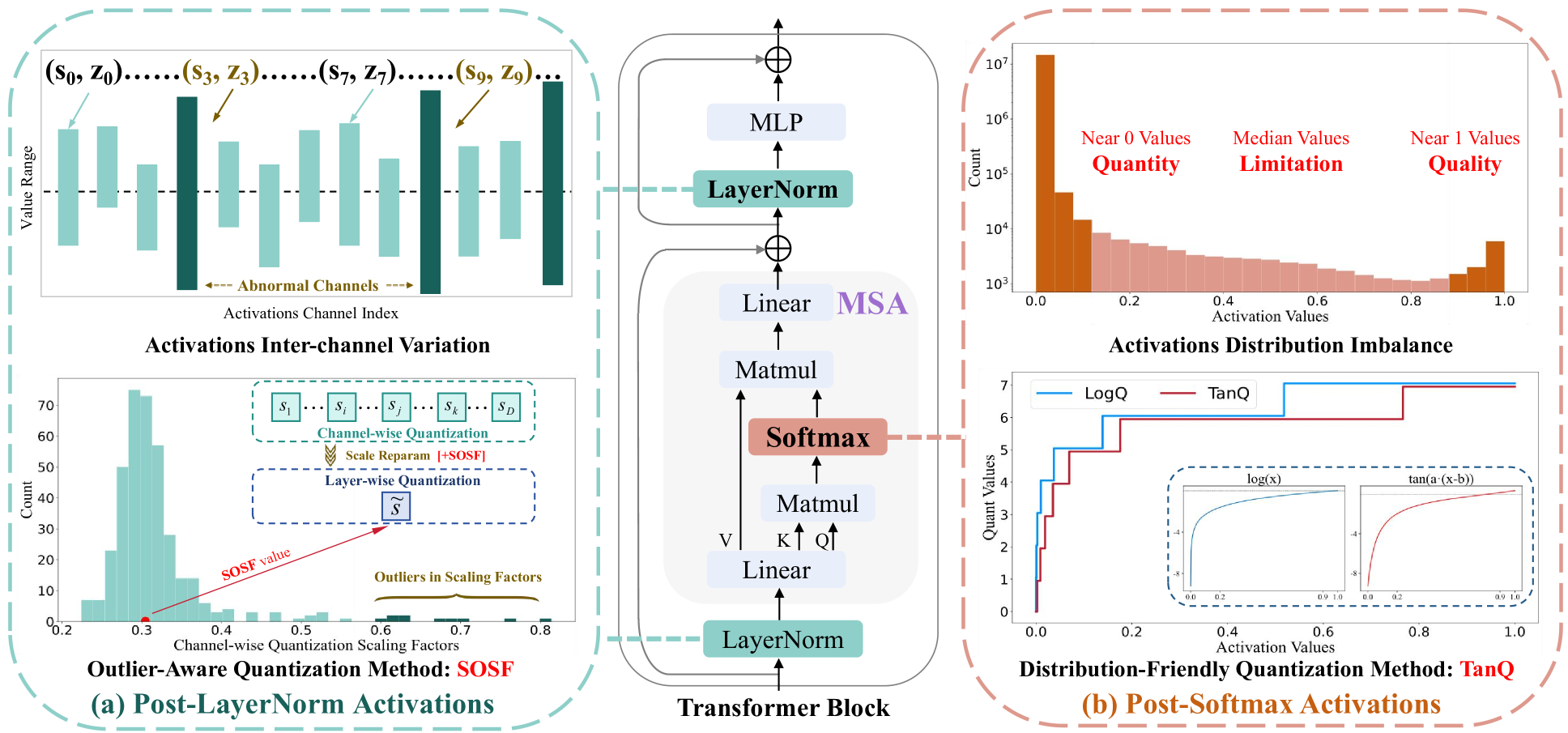
DopQ-ViT: Towards Distribution-Friendly and Outlier-Aware Post-Training ...
GitHub - zhexinli/Q-ViT: Official source code of Q-ViT: Fully ...
GitHub - megvii-research/FQ-ViT: [IJCAI 2022] FQ-ViT: Post-Training ...
Yanjing Li, Sheng Xu, Baochang Zhang, Xianbin Cao, Peng Gao, Guodong ...
(PDF) Q-ViT: Accurate and Fully Quantized Low-bit Vision Transformer
Q-ViT: Accurate and Fully Quantized Low-bit Vision Transformer | DeepAI
NeurIPS Poster Q-ViT: Accurate and Fully Quantized Low-bit Vision ...
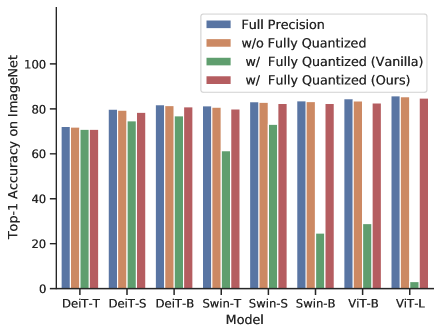
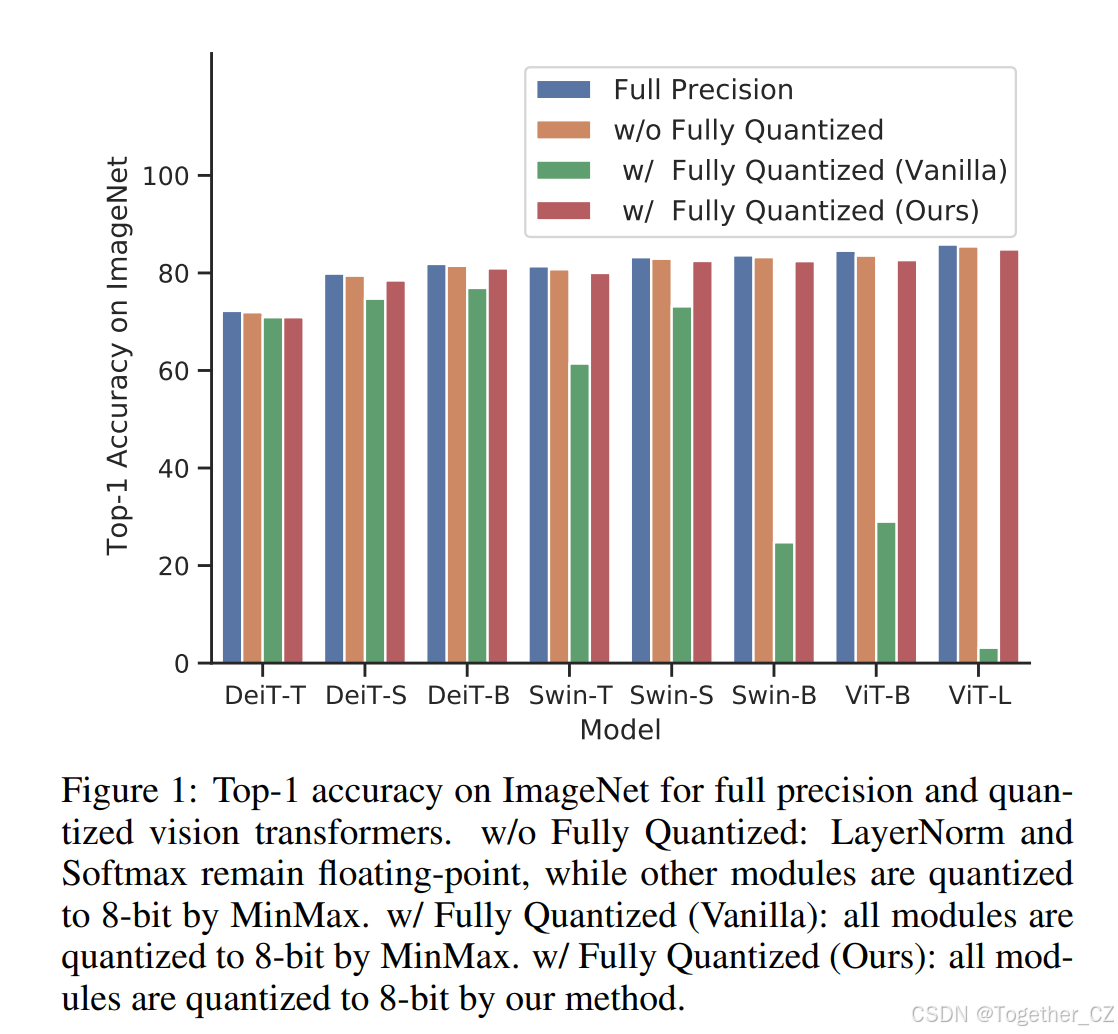
Figure 1 from Q-ViT: Accurate and Fully Quantized Low-bit Vision ...
FQ-ViT | Less is More
Figure 1 from ADFQ-ViT: Activation-Distribution-Friendly Post-Training ...
Figure 2 from RepQ-ViT: Scale Reparameterization for Post-Training ...
GitHub - zkkli/RepQ-ViT: [ICCV 2023] RepQ-ViT: Scale Reparameterization ...
[2208.05163] Auto-ViT-Acc: An FPGA-Aware Automatic Acceleration ...
GitHub - DD-DuDa/awesome-vit-quantization-acceleration: List of papers ...
Evaluating the components of Q-ViT based on ViT-S backbone. | Download ...
旷视提出Q-ViT:视觉Transformer的完全可微量化 - 知乎
Paper page - RepQ-ViT: Scale Reparameterization for Post-Training ...
M$^2$-ViT: Accelerating Hybrid Vision Transformers with Two-Level Mixed ...
FQ-Conv-ViT: A quantized convolutional vision transformer model for ...
Comparing performance across 12 random seeds for 8W8A ViT-Base. 10/12 ...